Natural Language Processing
Ability of computers to process and analyse large amounts of natural language data
- NLP is a combination of Computer Science, Artificial Language and Human Language
- N-Grams **** Play an important role in NLP
An NLP Pipeline consists of:
-
Data Acquisition
-
Text Preparation
-
Feature Engineering
-
Modelling
Data Acquisition
Process of acquiring data from different sources
Text Preparation
Working on data to make it representable / processable
-
Cleaning
- Html tags cleaning
- Removing emojis
- Spelling checker
-
Basic Preprocessing
- Tokenisation (sentence or word)
- Stop word cleaning
- Stemming / Lemmatisation
- Lower case conversion
- Language detection
-
Advance Preprocessing
- POS tagging
- Parsing
- Coreference resolution
Embedding / Vectorisation / Feature Engineering
Converting words and sentences into numeric vectors for use with computational algorithms
- The process of representing a token/a sentence as a numerical vector
- It uniquely identifies a work
- It makes it possible to apply arithmetic operations
Some types of Embeddings are:
-
One Hot Encoding
-
Bag of Words (BOW)
-
Term Frequency-Inverse Document Frequency (TF-IDF)
-
Word2Vec
-
GloVe
-
Fast Text
-
Transformers
Embeddings always have defined dimensions
- Sparse and Dense Vectors are two categorisation for representing words
- Sparse Embedding Techniques are highly dependent on the corpus and particularly the vocabulary size
- Dense Embedding Techniques on the other hand are not dependant entirely on corpus and are flexible
One Hot Encoding
Every word is represented as a unique ‘One-Hot’ binary vector of 0s and 1s
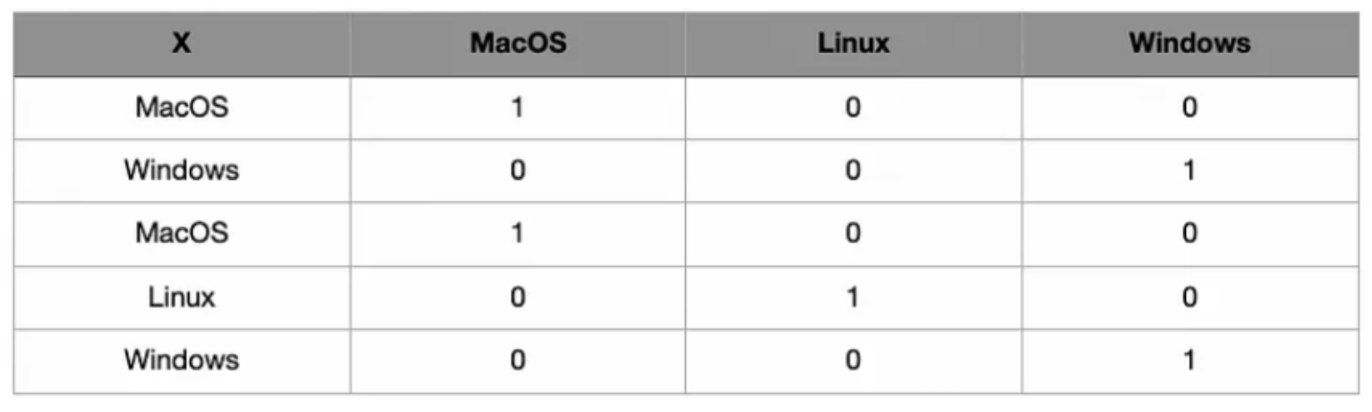
For every unique word in the vocabulary, the vector contains a single 1 and rest all values are 0s, the position of 1 in the vector uniquely identifies a word.
Bag of Words (BOW)
A text (such as a sentence or a document) is represented as the bag (multi-set) of its words, disregarding grammar and even word order but keeping multiplicity.
-
Measure of the presence of known words
-
Vocabulary of known words
Reviews

Unique Words

BOW for Review 4 Document

After converting the documents into such vectors we can compare different sentences and calculate the Euclidean distance between them so as to check if two sentences are similar or not. If there would be no common words distance would be much larger and vice-versa.
BOW doesn’t work very well when there are small changes in the terminology as we are using here, we have sentences with similar meaning but with just different words.
Term Frequency-Inverse Document Frequency (TF-IDF)
Generates Sparse Vectors / Embeddings
TF-IDF is a numerical statistic that is intended to reflect how important a word is to a document in a collection or corpus
The tf–idf value increases proportionally to the number of times a word appears in the document and is offset by the number of documents in the corpus that contain the word.
It is established as follow:
- Count the number of times each word appears in a document
- Calculate the frequency that each word appears in a document out of all the words in the document
Term Frequency
Term frequency (TF) shows how frequently an expression (term, word) occurs in a document
Inverse Document Frequency
IDF is a measure of how much information the word provides, i.e., if it’s common or rare across all documents
It is the logarithmically scaled inverse fraction of the documents that contain the word
TF-IDF gives larger values for less frequent words in the document corpus.
TF-IDF value is high when both IDF and TF values are high i.e the word is rare in the whole documents but frequent in a document.
Example
Sentence 1: The car is driven on the road
Sentence 2: The truck is driven on the highway
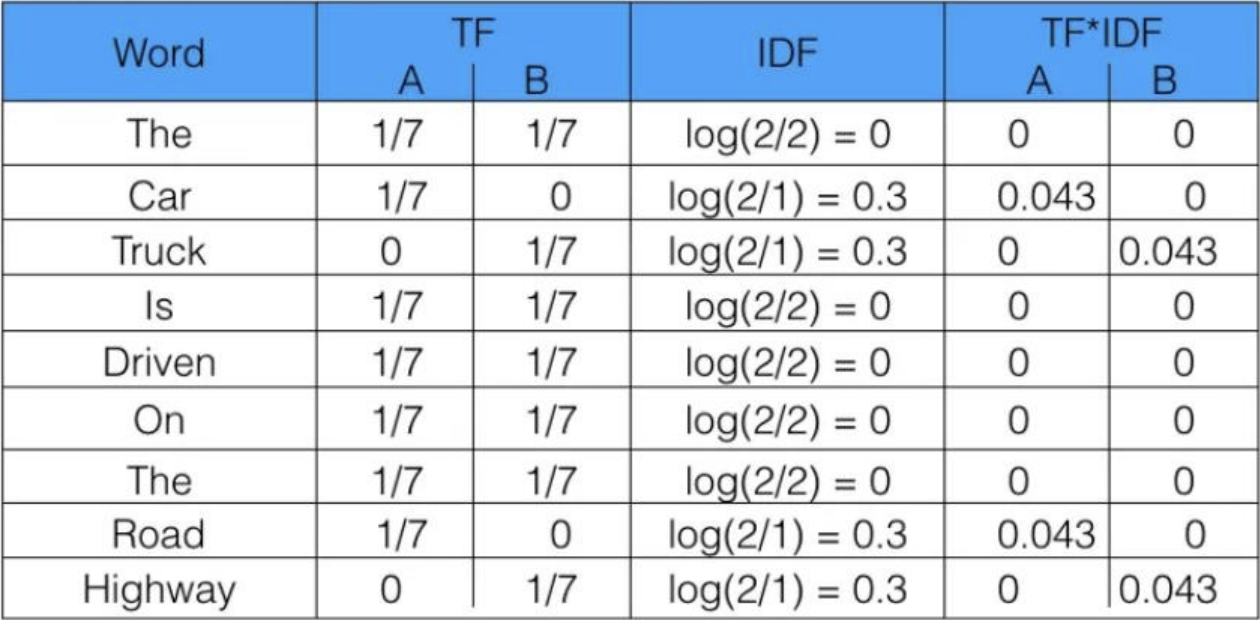
Shortcomings
- Can lead to Sparse Vectors which will ultimately add to our computational cost
Pointwise Mutual Information (PPMI)
Generates Sparse Vectors / Embeddings
- Generate information / gain using the probabilities of the single and co-occurred words
Word2Vec
Generates Dense Vectors / Embeddings
Vectorisation technique that utilises prediction techniques
CBOW
Continuous Bag of Words
We train a Neural Network using the surrounding words of a word with a defined context window
CBOW is used when the corpus is very large
-
Context Word
- Words surrounding the actual word we need
- Given as Input
-
Target Word
- Word we need to predict and work on
- Given as Output
-
Self-Supervised Learning Algorithm
-
We have a Sliding Window
-
Each vocabulary word is made as a target one by one while the words in its context window are feed as input
-
The underlying Neural Network is also called as a Black Box
The reason is that we cannot define the meanings of the weights in our Neural Network and also cannot assign embeddings / weights own their own
-
The weights learned / utilised by the model at the end / output layer are our word embeddings and each word has their own weights, thus embedding
-
The count of the weights for each word is also our embedding size
-
Architecture
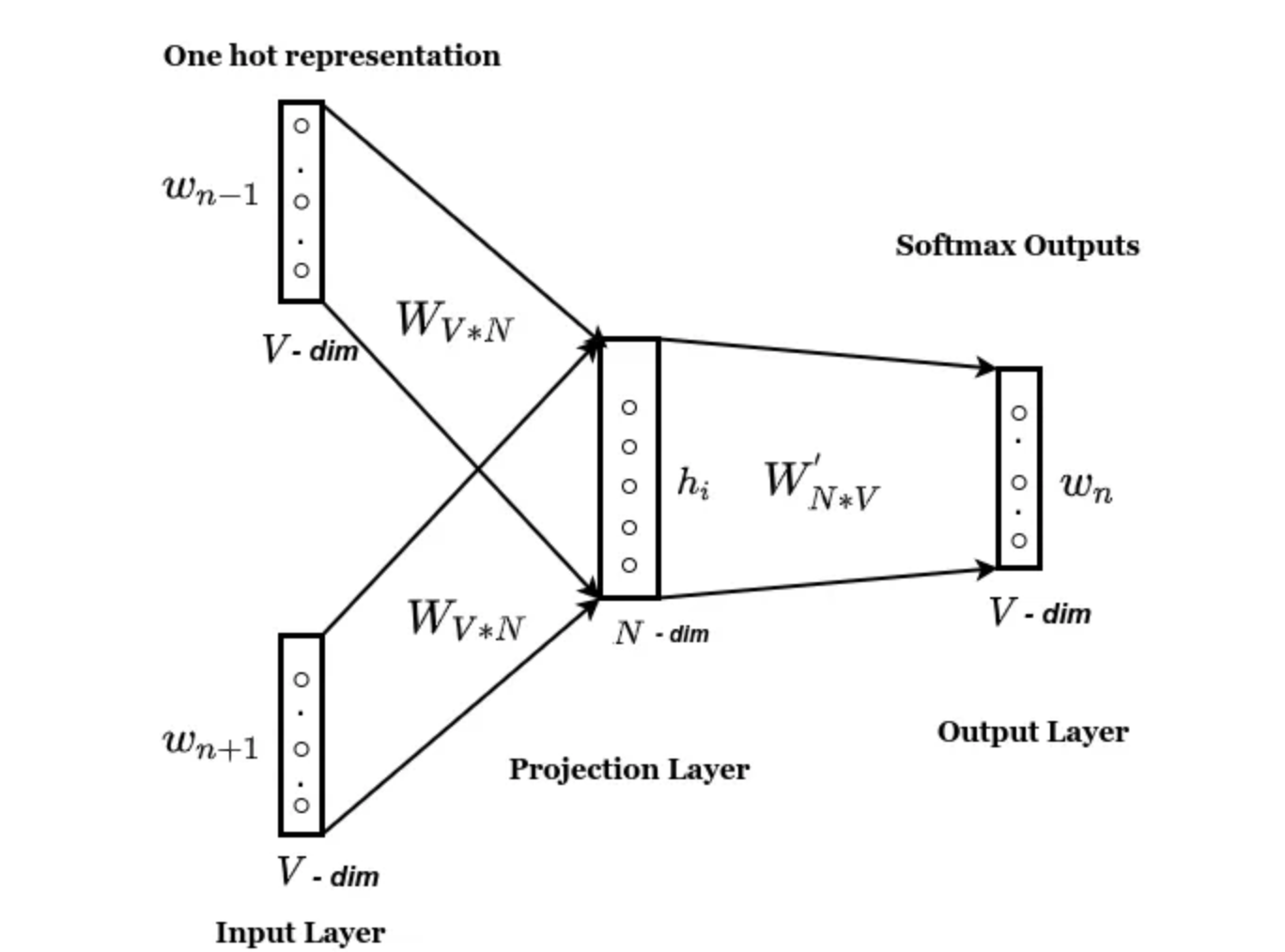
Skip Gram
Skip Gram is used when the corpus is small
-
Target Word
- Word for which we need to predict the embedding and work on
- Given as Input
-
Context Word
- Words surrounding the actual word we need
- Given as Output
-
Self-Supervised Learning Algorithm
-
We use the same sliding window as in the case of CBOW
-
Neural Network is again used as the underlying model to predict embeddings
- However, the architecture of the network is reversed from as it was in CBOW
-
-
Negative Sampling is used to feed the words and data into the network
Architecture
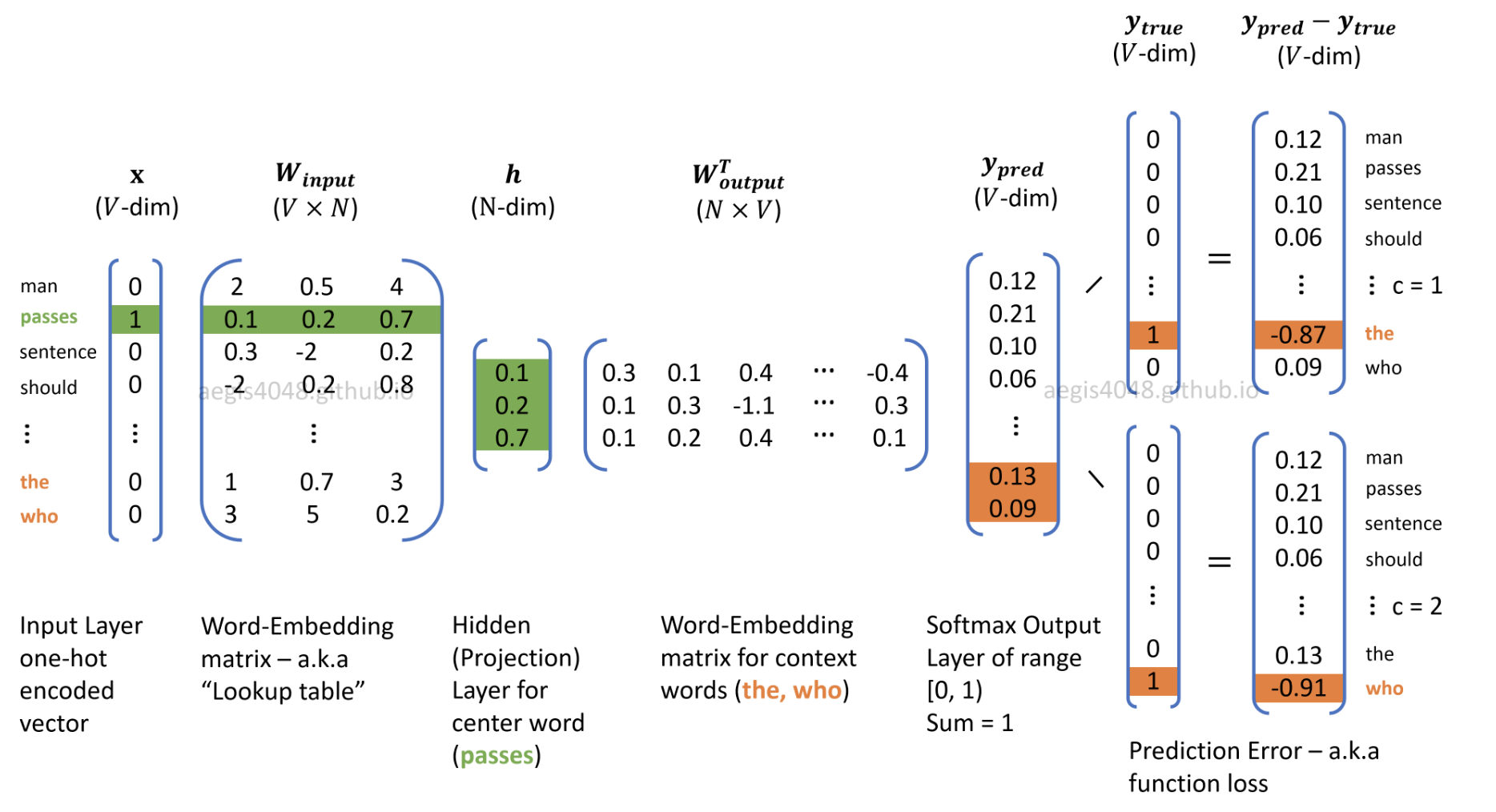
Language Modelling
A language model learns to predict the probability of a sequence of words.