The process of extracting data into the warehouse from operational systems, also called Acquisition.
We can Extract, Transform and Load. or
We can Extract, Load and then Transform
ETL is extract, transfer, load in which transformation takes place on a transformation server using weather an ‘engine’ or by generated code.
ELT is extract, load, transform in which data transformations take place in a relational database on the data warehouse server.
An ETL Process typically involves the following steps:
- Extracts from source systems
- Data movement
- Transformations
- Data loading
- Index maintenance
- Statistics collection
- Summary data maintenance
- Data mart construction
- Backups
Stakeholders
- Extracting Techniques
- Transforming Techniques
- Loading Techniques
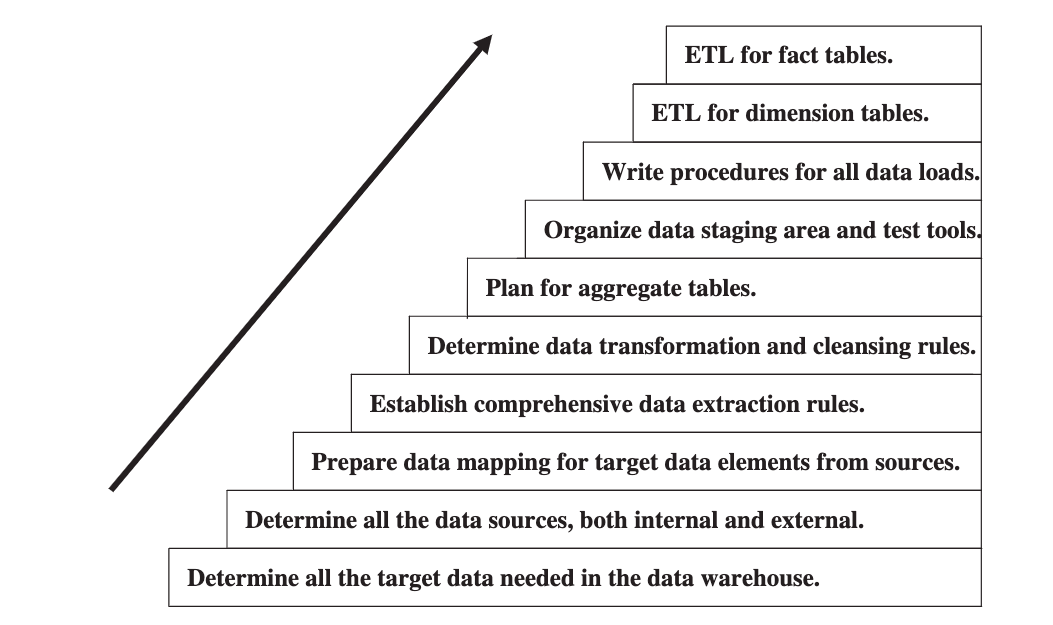
Major steps in the ETL process
Data Pipelining
The process of dividing data into chunks and concurrently run all the dependent jobs when the chunk is ready or collected
Starting the next job as soon some data of the the prerequisite job is ready to be executed
An example could be:
- Lets say we want to join three tables. The third table cannot be joined unless the first two tables are joined. By implementing pipelines here, we can join first few rows of the first two joined tables as soon as they are available with the third table.
Data Extraction
The process of fetching and getting data from operational systems
Techniques
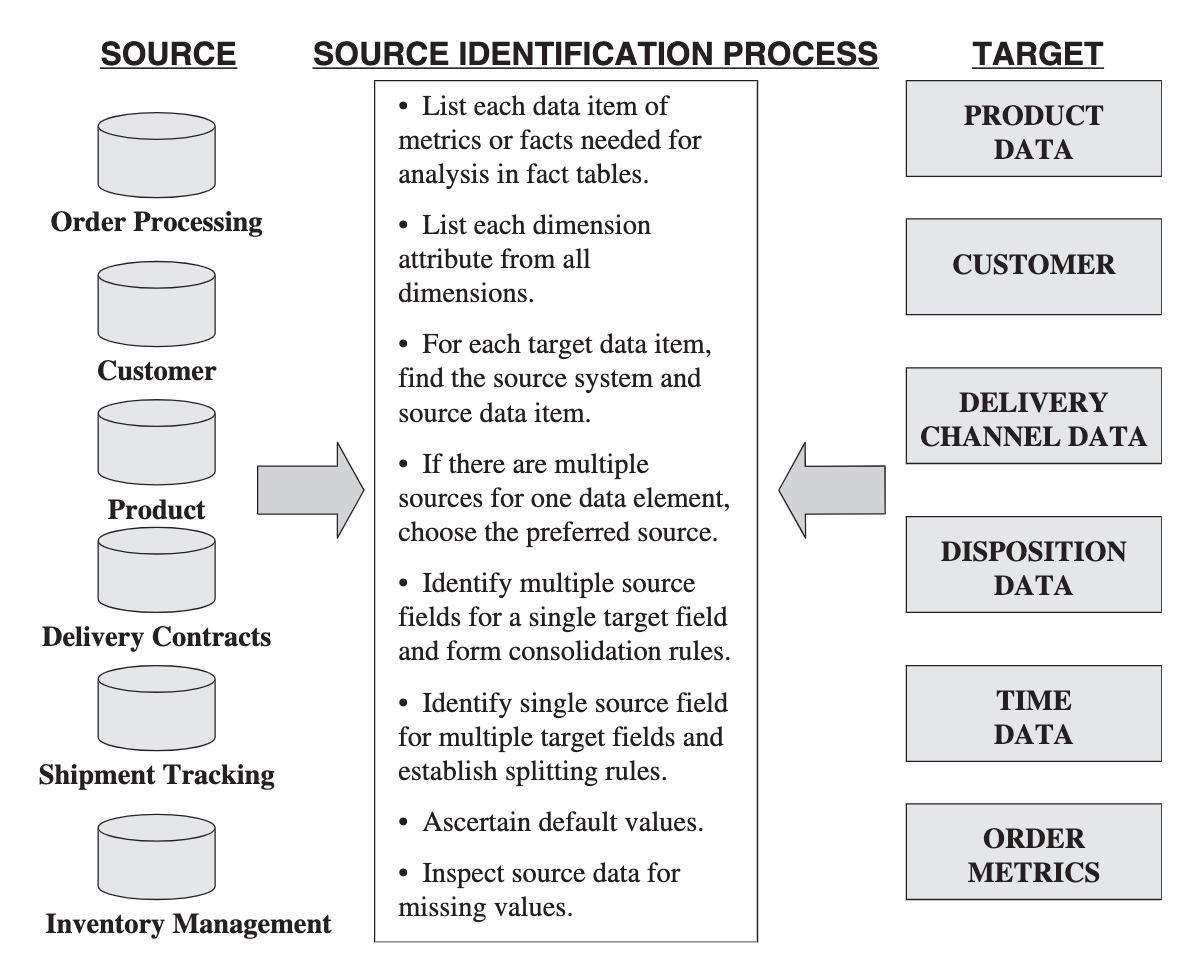
Source identification: a stepwise approach
Deferred Source Data
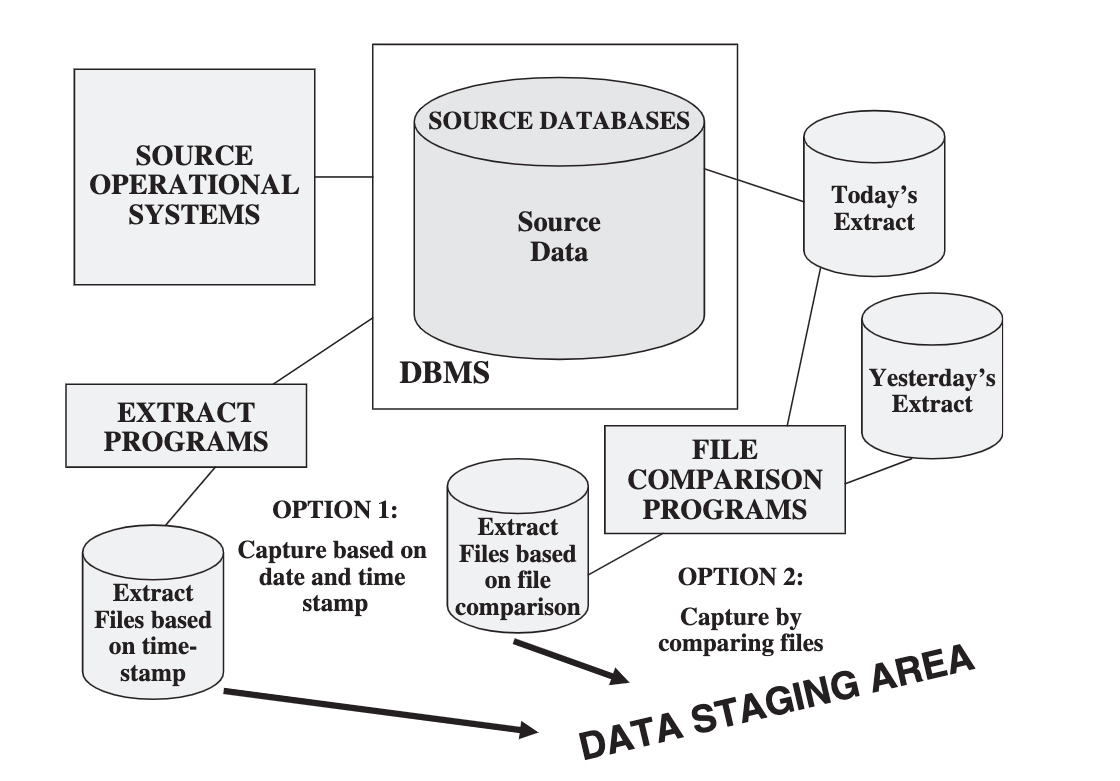
Deferred data extraction do not capture the changes in real time. The capture happens later.
Options for Deferred Data Extraction
Deferred Extraction Techniques
Data and Time Stamps
Comparing Files
This technique necessitates the keeping of prior copies of all the relevant source data. Though simple and straightforward, comparison of full rows in a large file can be very inefficient. However, this may be the only feasible option for some legacy data sources that do not have transaction logs or time stamps on source records
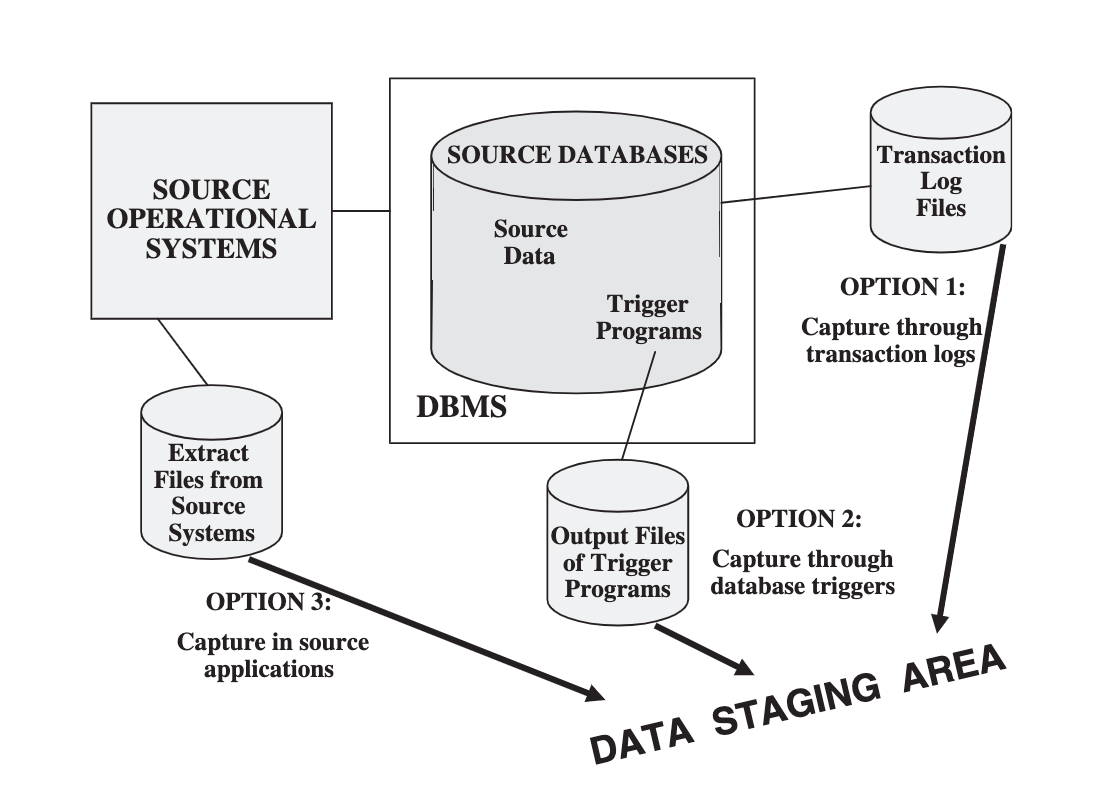
Immediate Data Extraction
Options for Immediate Data Extraction
Immediate Extraction Techniques
Transaction Logs
Database Triggers
Get data from the transactional systems based on the triggers defined. A trigger will run at a specific event and when that event occurs, we will feed the data into the warehouse (put it into the data staging area).
Source Application
We can configure our source or transaction systems to send data to the warehouse based on our specifications.
Data Capture Techniques: Advantages and Disadvantages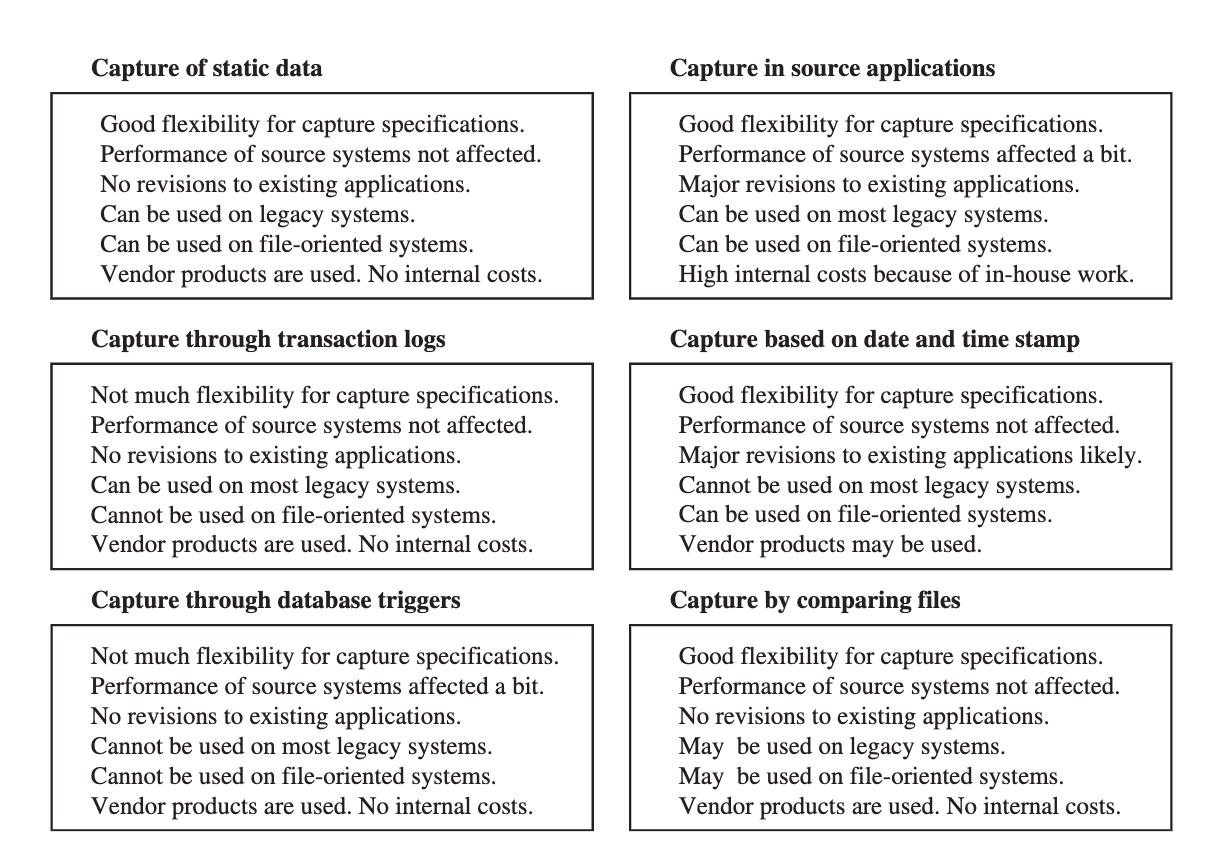
Data Loading
The process of inserting the data into our warehouse
We must also worry about rolling off old data as its economic value drops below the cost for storing and maintaining it.
A pattern exists between data freshness and insert efficiency. Buffering rows for insertion allows for fewer round trips to RDBMS but waiting to accumulate rows into the buffer impact data freshness
Less Efficiency = Less Freshness
Techniques
Choice in loading strategy depends in tradeoffs in data freshness and performance, as well as data volatility characteristics.
What is the goal?
-
Increased data loading performance
-
Increased data freshness
But we can only have one thing at a time
Full Data Refresh
Completely reload table on each refresh or when loading into the DWH
Initially when the DWH is empty, this technique is used to populate it however, it can also be used when cost of insertion is way less than the cost of updating existing records
Updating 1 Row is always costly than inserting a new Row
Steps:
-
Load table using Block Slamming
- Block Slamming / Bulk Insert is the process when large records of data needs to be inserted
-
Build Indexes(Since pervious indexes will definitely wipe out)
-
Collect Statistics(Maintain MetaData)
When to Use It
This technique is used when high percentage (typically 10%) of rows in the data change on each refresh
Example could be reference lookup tables or account tables where balances change on each refresh.
Performance Hints
- Make sure that Referential Integrity is disabled during the process of insertion
- Make sure that table logs are disabled too
- Make sure to build indices after table has been loaded
Incremental Data Refresh
Incrementally load new data into existing target table that has already been populated from previous loads
Either load directly into the table or use a shadow table strategy
Indices are preserved in both strategies, however there is a significant cost to holding it.
Directly Loading into the Table
- Re-collect statistics if demographics have changes significantly
- Typically requires a table lock to be taken during block slamming operations
Shadow Table Implementation
- Use block slamming into empty
shadow table having identical structure to target table - Insert-select operation from shadow table to target table will preserve indices
Cost of Holding Indices
The cost of holding indices is about 2-3 times the resources of the actual row insertion of data into a table
Consider dropping and re-building index structures if the number of rows being incrementally loaded is more than 10% of the size of the target table
Trickle Feed with Continuous Updates
Data is made available to DWH
immediately rather than waiting for batch loading to completeMuch higher overhead for data acquisition on a per record basis as compared to batch strategies
- We load one row at a time instead of working in batches